Simone Rossetti
Applied Researcher · Pursuing R&D in embodied AI · AI @ DIAG & ALCOR Lab

⬆️ Rainbow Mountain, Peru
📍 Rome, Italy
👋 Hi, I’m Simone, an AI Research Engineer working at the intersection of Computer Vision and Natural Language Processing. My work focuses on representation learning, vision-language alignment, and weakly, semi-, and self-supervised learning for semantic and instance-level visual understanding.
📚 My research interests lie in Multimodal Learning, Vision-Language Models (VLMs), and Vision-Language-Action Models (VLAMs). I am particularly interested in grounding language into dense visual predictions (segmentation, tracking, affordances) and leveraging foundation models for zero- and few-shot transfer in structured vision tasks. A recurring theme is uncertainty modeling and probabilistic priors to improve robustness, calibration, and data efficiency under limited or noisy supervision.
🚀 My goal is to continue in research and development in embodied AI. From March 2026 I am in a deliberate transition toward roles where I can do exactly that: high-impact, production-grade intelligent systems. My focus is on multimodal foundation models (Vision-Language and Vision-Language-Action architectures), large-scale Transformer systems, and probabilistic modeling for sequential decision processes—combined with structured analysis of research trends in embodied AI and generative modeling, and hands-on prototyping to assess architectural trade-offs, scalability, and deployment feasibility.
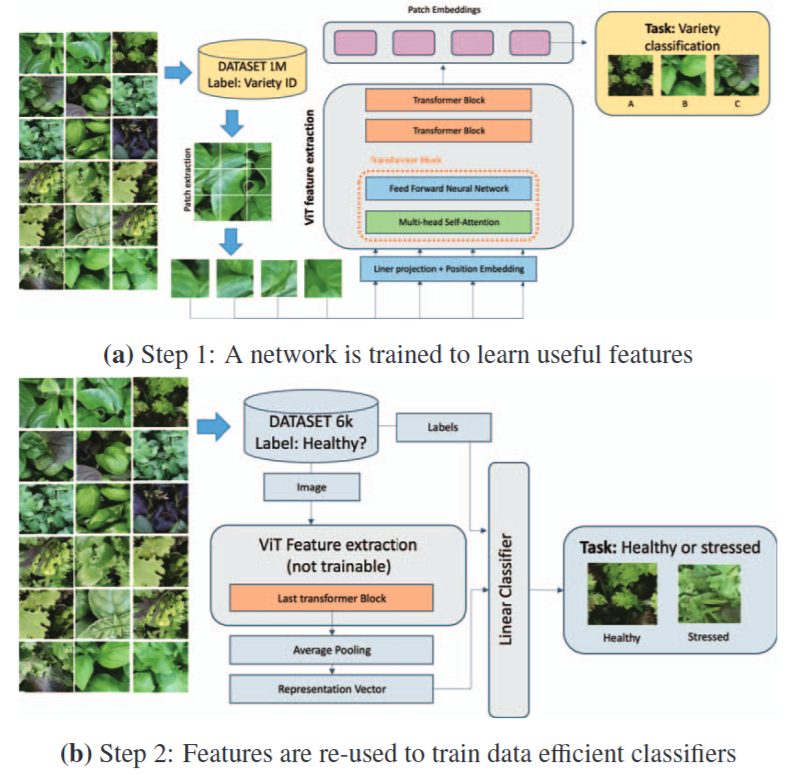
🔙 I co-founded DeepPlants (Sep 2021 – Feb 2026), where I led research and engineering teams building production-grade, agentic AI systems for micro-farming management, plant phenotyping, and agri-tech automation. My experience spans the full research-to-production pipeline, from dataset design and large-scale multi-GPU training to model optimization and real-world deployment.
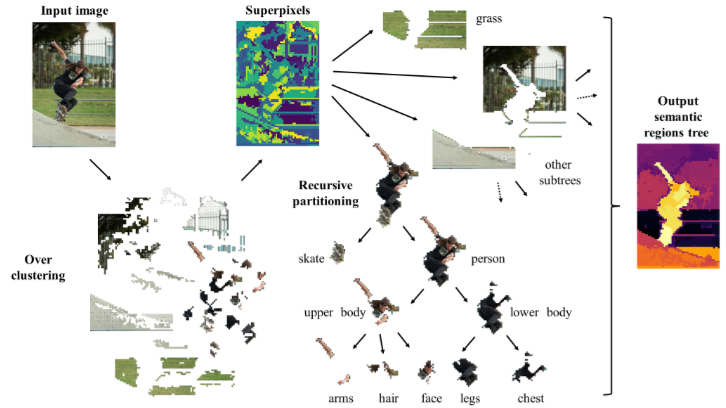
🔙 Previously, I was an AI Research Fellow at ALCOR Lab (Sapienza University of Rome), contributing to peer-reviewed research in computer vision, with a focus on instance segmentation and tracking and activity recognition.
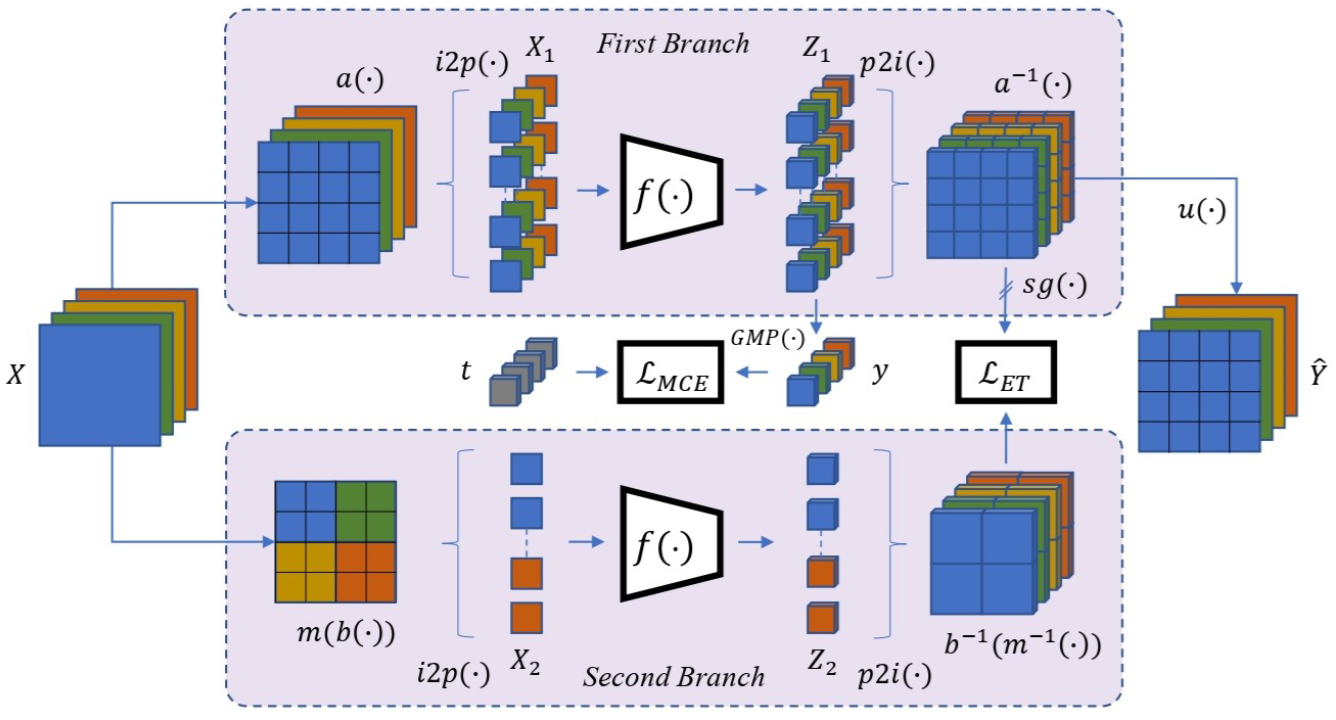
🎓 I earned a PhD in Computer Science Engineering from DIAG, Sapienza University of Rome. My doctoral research focused on reducing supervision in semantic segmentation through Bayesian prior modeling and structured regularization. I hold an MSc in AI & Robotics and a BSc in Computer Engineering, with a background in automation and perception-action systems.
📄 My work has been presented at NeurIPS, ECCV, and ICCV. Selected publications and highlights are available on the Publications page.
📮 For collaborations reach out at simone[dot]rossetti[at]live[dot]com.
news
| Mar 01, 2026 | Leaving DeepPlants — pursuing R&D in embodied AI |
|---|---|
| Oct 01, 2025 | CABBO applying to COSMIC and SmarTerra open calls |
| Jan 29, 2025 | Lessons learned while designing a multimodal benchmark for agricultural decision support |
| Jan 20, 2025 | CABBO – multimodal AI agent for EU micro-farming |
| Sep 15, 2024 | Since September 2024 I have been leading the multimodal learning team at DeepPlants, focusing on combining vision, language and agronomic signals to build robust, data-efficient models for agricultural applications. |