publications
publications by categories in reversed chronological order.
2025
- unpublished
 CABBAGE: Comprehensive Agricultural Benchmark Backed by AI-Guided EvaluationSimone Rossetti*, Paolo Gatti*, and Davide Palleschi*More Information can be found here. , 2025
CABBAGE: Comprehensive Agricultural Benchmark Backed by AI-Guided EvaluationSimone Rossetti*, Paolo Gatti*, and Davide Palleschi*More Information can be found here. , 2025 - Reducing supervision in semantic segmentation through advancements in bayesian prior modellingSimone Rossetti2025
Over the past few years, semantic segmentation has witnessed significant advancements, particularly with the emergence of Vision Transformers (ViTs). However, from 2021 through 2022, when this research was begun, the adoption of ViTs in semantic segmentation was not yet widespread. The field continued to face challenges due to the labour-intensive and costly nature of annotating data for semantic segmentation. This thesis addresses these challenges by exploring reduced-supervision and unsupervised methodologies to make semantic segmentation more efficient and accessible through three interconnected research projects. In the first study, we investigate the robustness of classification pre-trained deep neural networks for semantic segmentation without spatial guidance on object positions—a common challenge in weakly supervised semantic segmentation (WSSS). We address this by extracting high-level information encoded within model representations through low-level information degradation and multi-view information bottleneck techniques. By leveraging geometric priors on image composition—specifically, the principle of geometric equivariance under affine transformations—we enhance the model’s ability to segment images accurately. Our empirical results demonstrate that ViTs, when combined with appropriate computation of Class Activation Maps (CAMs), are significantly more effective in achieving high-quality WSSS than the previously favoured deep convolutional networks (CNNs). Building on these findings and the limitations of current approaches, our second study aims to mitigate the effects of the lack of spatial information in WSSS with a prior assumption about the spatial distribution of categories across natural images. We propose that objects appear at different scales within images, either in the foreground or background, leading to a similar spatial distribution for each category over a large set of images. By incorporating this prior, we avoid the side effects of unbalanced data distribution among visual concepts and enhance model generalization in WSSS. Our method achieves new state-of-the-art performance on several benchmarks. We model this prior through class frequencies and matrix balancing, an approach derived from optimal transport theory. Unlike contrastive learning methods, our approach operates efficiently with small batches without memory bank requirements, demonstrating the significant potential of cluster-based principles to enhance WSSS, reaching results comparable to fully supervised methods. The third study explores the realm of unsupervised semantic segmentation (USS) by introducing a deep recursive spectral clustering technique that leverages the hypothesis that semantics is hierarchical. While conventional methods often rely on dataset-specific predefined assumptions, such as object-part decomposition and salient semantic regions, our data-driven approach segments images at multiple levels of granularity without prior knowledge of the scene’s structure. This algebraic method recursively refines segmentation based on the inherent semantic properties of the data, providing a flexible and robust way of grouping pixels. We experimentally demonstrate that the method excels in discovering fine and coarse semantic structures in a fully unsupervised manner, offering substantial improvements over traditional models that often struggle with granularity and require dataset-specific priors hindering scalability. Altogether, these studies advance semantic segmentation by progressively reducing the level of required supervision and demonstrating the effectiveness of minimizing reliance on pixel-level annotations through appropriate prior assumption modelling. These contributions align with the evolving trends in semantic segmentation during this research and pave the way for future developments in computer vision.
@article{rossetti2025reducing, title = {Reducing supervision in semantic segmentation through advancements in bayesian prior modelling}, author = {Rossetti, Simone}, booktitle = {PhD Thesis}, year = {2025}, publisher = {Universit{\`a} degli Studi di Roma" La Sapienza"}, }
2024
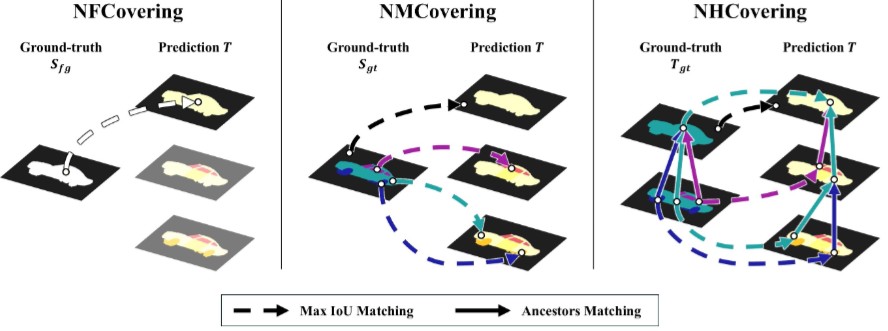
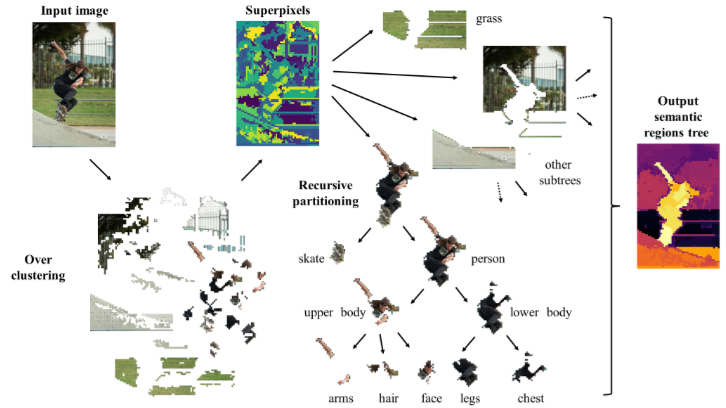
- Hierarchy-Agnostic Unsupervised Segmentation: Parsing Semantic Image StructureSimone Rossetti†* and Fiora Pirri†*In Advances in Neural Information Processing Systems. More Information can be found here. , 2024
Unsupervised semantic segmentation aims to discover groupings within images, capturing objects’ view-invariance without external supervision. Moreover, this task is inherently ambiguous due to the varying levels of semantic granularity. Existing methods often bypass this ambiguity using dataset-specific priors. In our research, we address this ambiguity head-on and provide a universal tool for pixel-level semantic parsing of images guided by the latent representations encoded in self-supervised models. We introduce a novel algebraic approach that recursively decomposes an image into nested subgraphs, dynamically estimating their count and ensuring clear separation.The innovative approach identifies scene-specific primitives and constructs a hierarchy-agnostic tree of semantic regions from the image pixels. The model captures fine and coarse semantic details, producing a nuanced and unbiased segmentation. We present a new metric for estimating the quality of the semantic segmentation of discovered elements on different levels of the hierarchy. The metric validates the intrinsic nature of the compositional relations among parts, objects, and scenes in a hierarchy-agnostic domain. Our results prove the power of this methodology, uncovering semantic regions without prior definitions and scaling effectively across various datasets. This robust framework for unsupervised image segmentation proves more accurate semantic hierarchical relationships between scene elements than traditional algorithms. The experiments underscore its potential for broad applicability in image analysis tasks, showcasing its ability to deliver a detailed and unbiased segmentation that surpasses existing unsupervised methods.
@inproceedings{rossetti2024hierarchy, author = {Rossetti, Simone and Pirri, Fiora}, title = {Hierarchy-Agnostic Unsupervised Segmentation: Parsing Semantic Image Structure}, booktitle = {Advances in Neural Information Processing Systems}, year = {2024}, doi = {10.52202/079017-3139}, }
2023
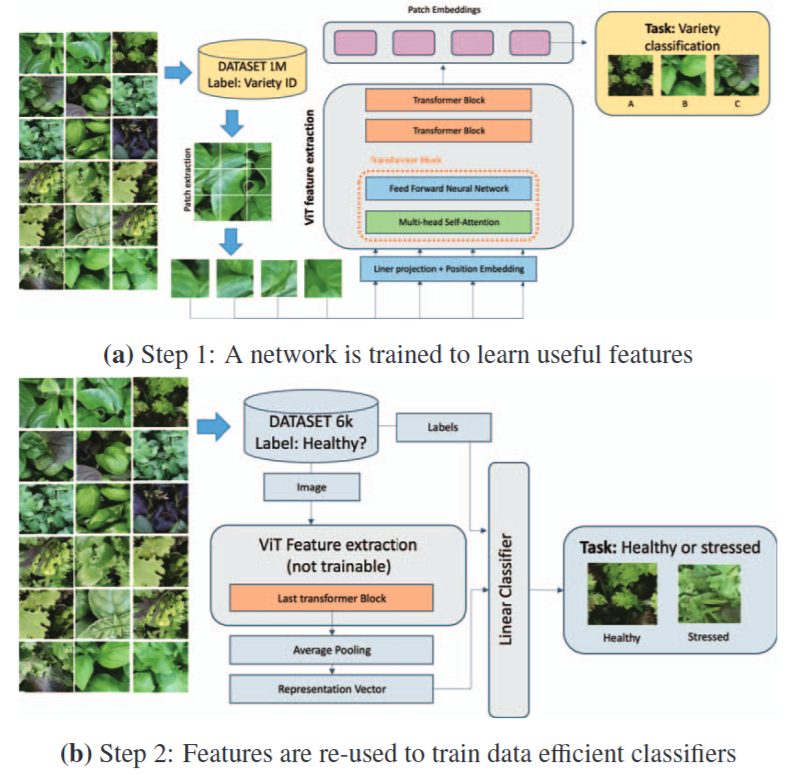
- A new Large Dataset and a Transfer Learning Methodology for Plant Phenotyping in Vertical FarmsNico Samà*, Etienne David°, Simone Rossetti†*, and 3 more authorsIn IEEE/CVF International Conference on Computer Vision Workshops. More Information can be found here. , Oct 2023
Vertical farming has emerged as a solution to enhance crop cultivation efficiency and overcome limitations in conventional farming methods. Yet, abiotic stresses significantly impact crop quality and increase the risk of food loss. The integration of advanced automation, sensor technology, and deep learning models offers a promising solution for quality monitoring addressing the limitations of stress-specific approaches. Due to the large range of possible quality issues, there is a need for a general method. This study proposes a new plant canopy dataset, dubbed AGM of 1M images, annotated with 18 classes, an in-depth analysis of its quality for its use in transfer learning, and a methodology for detecting canopy stresses in vertical farming. The present study trains ViTbase8, ViTsmall8, and ResNet50 both on ImageNet and the proposed dataset on crop classification. Features from AGM and ImageNet are used for a downstream task on healthy and stress detection using a small annotated validation dataset obtaining 0.97%, 0.93%, and 0.92% best accuracy with the AGM features. We compare with standard datasets like Cassava, PlantDoc, and RicePlant obtaining significant accuracy. This research contributes to improved crop quality, prolonged shelf life, and optimized nutrient content in vertical farming, enhancing our understanding of abiotic stress management.
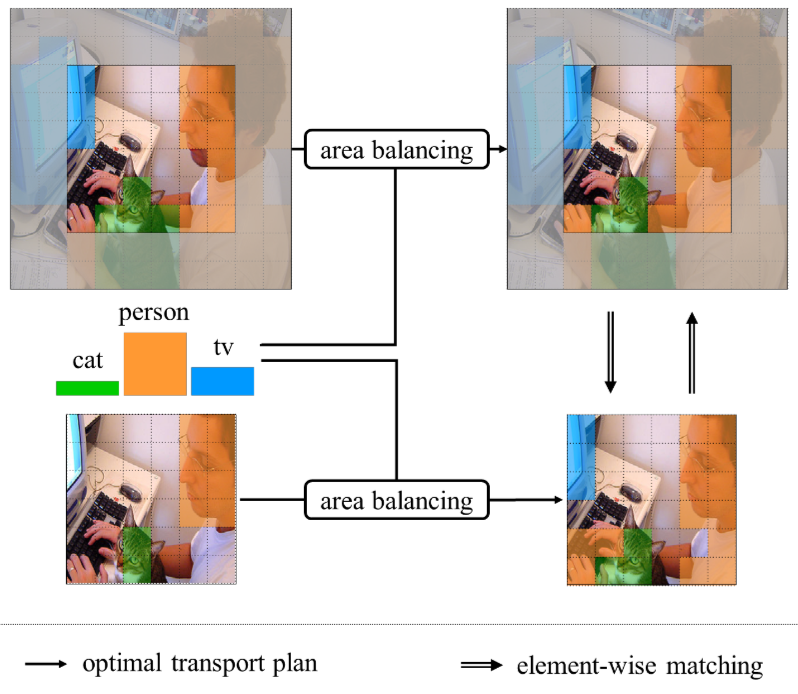
@inproceedings{sama2023a, author = {Samà, Nico and David°, Etienne and Rossetti, Simone and Antona°, Alessandro and Franchetti°, Benjamin and Pirri, Fiora}, title = {A new Large Dataset and a Transfer Learning Methodology for Plant Phenotyping in Vertical Farms}, booktitle = {IEEE/CVF International Conference on Computer Vision Workshops}, month = oct, year = {2023}, pages = {540-551}, doi = {10.1109/ICCVW60793.2023.00061}, } - Removing supervision in semantic segmentation with local-global matching and area balancingSimone Rossetti†*, Nico Samà*, and Fiora Pirri†*arXiv preprint arXiv:2303.17410. More Information can be found here. , 2023
@article{rossetti2023removing, title = {Removing supervision in semantic segmentation with local-global matching and area balancing}, author = {Rossetti, Simone and Sam{\`a}, Nico and Pirri, Fiora}, journal = {arXiv preprint arXiv:2303.17410}, year = {2023}, }
2022
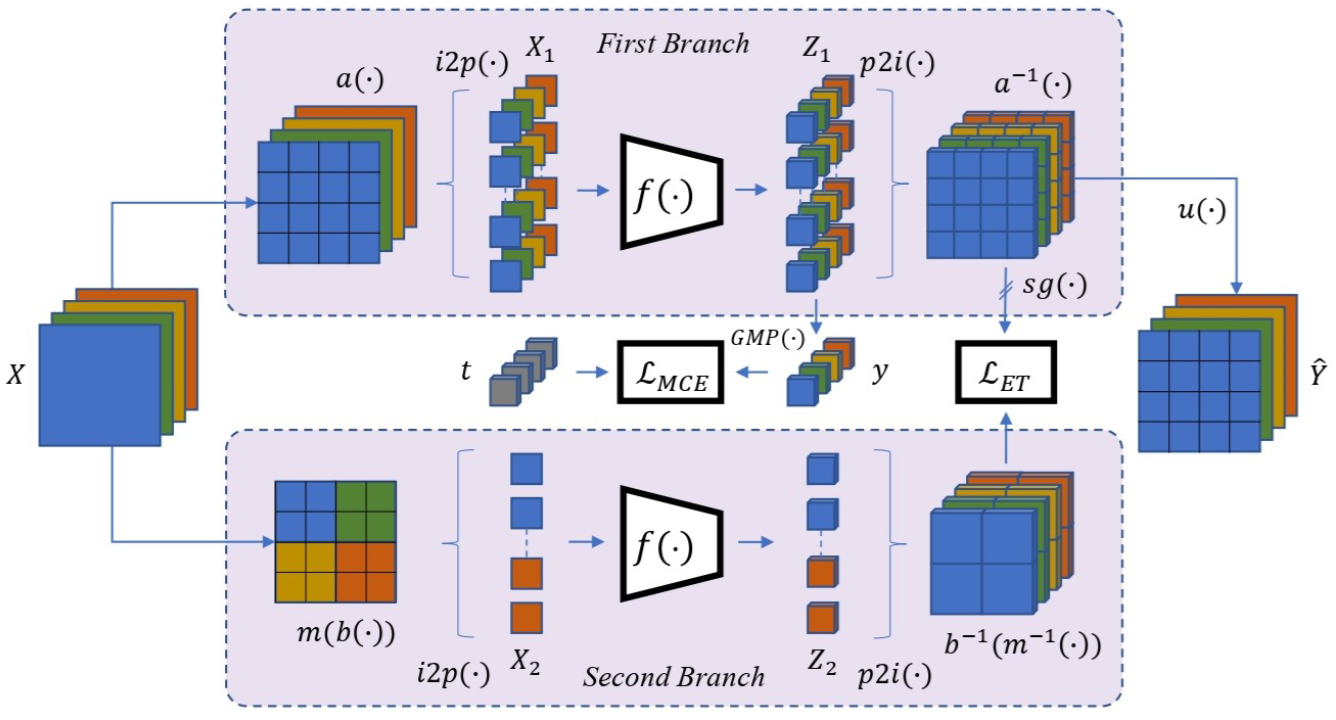
- Max Pooling with Vision Transformers Reconciles Class and Shape in Weakly Supervised Semantic SegmentationSimone Rossetti†*, Damiano Zappia*, Marta Sanzari*, and 2 more authorsIn Computer Vision – ECCV. More Information can be found here. , 2022
Weakly Supervised Semantic Segmentation (WSSS) research has explored many directions to improve the typical pipeline CNN plus class activation maps (CAM) plus refinements, given the image-class label as the only supervision. Though the gap with the fully supervised methods is reduced, further abating the spread seems unlikely within this framework. On the other hand, WSSS methods based on Vision Transformers (ViT) have not yet explored valid alternatives to CAM. ViT features have been shown to retain a scene layout, and object boundaries in self-supervised learning. To confirm these findings, we prove that the advantages of transformers in self-supervised methods are further strengthened by Global Max Pooling (GMP), which can leverage patch features to negotiate pixel-label probability with class probability. This work proposes a new WSSS method dubbed ViT-PCM (ViT Patch-Class Mapping), not based on CAM. The end-to-end presented network learns with a single optimization process, refined shape and proper localization for segmentation masks. Our model outperforms the state-of-the-art on baseline pseudo-masks (BPM), where we achieve 69.3% mIoU on PascalVOC 2012 val set. We show that our approach has the least set of parameters, though obtaining higher accuracy than all other approaches. In a sentence, quantitative and qualitative results of our method reveal that ViT-PCM is an excellent alternative to CNN-CAM based architectures.
@inproceedings{rossetti2022max, author = {Rossetti, Simone and Zappia, Damiano and Sanzari, Marta and Schaerf, Marco and Pirri, Fiora}, editor = {Avidan, Shai and Brostow, Gabriel and Ciss{\'e}, Moustapha and Farinella, Giovanni Maria and Hassner, Tal}, title = {Max Pooling with Vision Transformers Reconciles Class and Shape in Weakly Supervised Semantic Segmentation}, booktitle = {Computer Vision -- ECCV}, year = {2022}, publisher = {Springer Nature Switzerland}, address = {Cham}, pages = {446--463}, isbn = {978-3-031-20056-4}, doi = {10.1007/978-3-031-20056-4_26}, }
2021
- Youtube-VOS
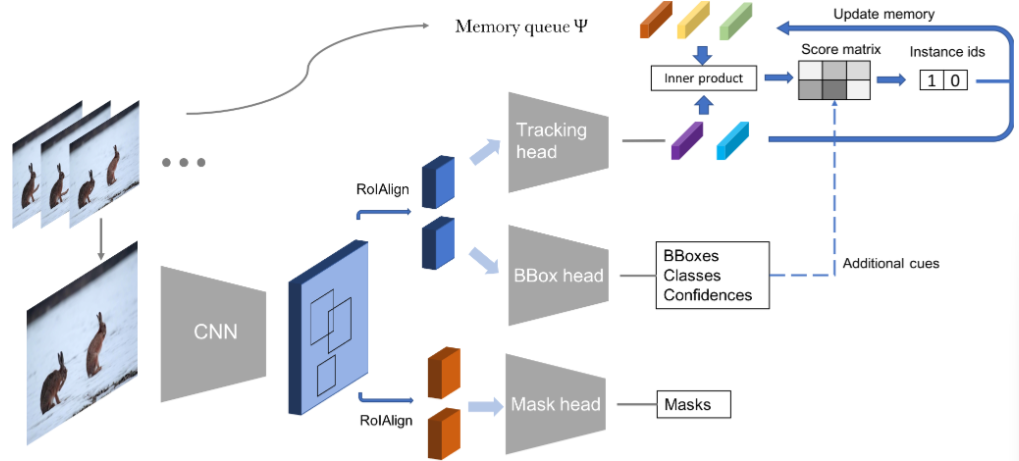 Video Instance segmentation Challenge 2021 with Y oloV 4Simone Rossetti*, Temirlan Zharkynbek*, and Fiora Pirri*Youtube-VOS Challenge. More Information can be found here. , 2021
Video Instance segmentation Challenge 2021 with Y oloV 4Simone Rossetti*, Temirlan Zharkynbek*, and Fiora Pirri*Youtube-VOS Challenge. More Information can be found here. , 2021@article{rossettivideo, title = {Video Instance segmentation Challenge 2021 with Y oloV 4}, author = {Rossetti, Simone and Zharkynbek, Temirlan and Pirri, Fiora}, year = {2021}, journal = {Youtube-VOS Challenge}, }